
Google on Wednesday, announced their expansion on Google Translate to support 24 under-sourced languages, including Ilocano through ‘unlocking zero-resource machine translation’.
Google created “monolingual datasets by developing and using specialized neural language identification models combined with novel filtering approaches” for these languages.Below is the complete list of new languages added to Google Translate in their update:
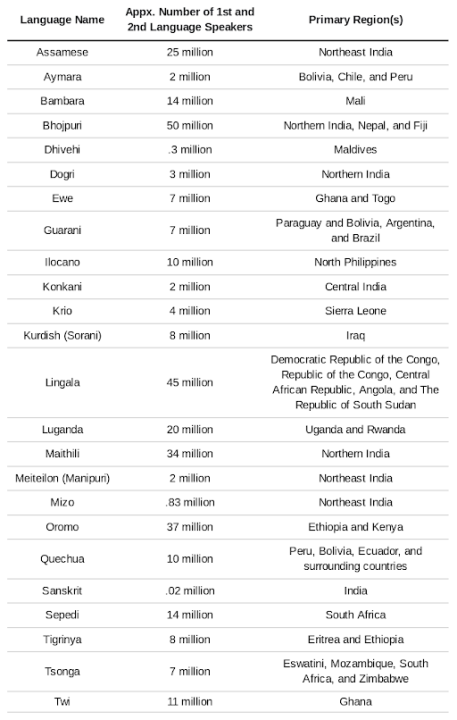
The update was part of Google’s effort in “Building Machine Translation Systems for the Next Thousand Languages.” Google describes building high-quality monolingual datasets for over a thousand languages that do not have translation datasets available and demonstrates how one can use monolingual data alone to train Machine Translation models.
Google said that the technology of Machine translation (MT) has made significant advancements in recent years, as deep learning has been integrated with natural language processing (NLP), and WMT research benchmark performance soared. Despite that, existing translation services only cover around 100 languages in total.
Languages that are overwhelmingly represented are European, and had largely overlooked high linguistic diversity in other regions such as Africa and the Americas.
Google states that there are two bottlenecks to address in building MT models for plethora of languages to reach sufficient quality: (1) data scarcity—”digitized data for many languages is limited and can be difficult to find on the web due to quality issues with Language Identification (LangID) models”; (2) modeling limitations—”MT models usually train on large amounts of parallel (translated) text, but without such data, models must learn to translate from limited amounts of monolingual text, which is a novel area of research.”
Google also presented relevant graphs and data, saying that “automatically gathering usable textual data for under-resourced languages is much more difficult than it may seem.”
As part of their research, Google also acknowledged contributions from over 100 people and institutions who are native speakers of the mentioned languages.
Moreover, Google stressed out that the translation quality produced by the new models still lags behind from the higher-resourced languages.
“These models are certainly a useful first tool for understanding content in under-resourced languages, but they will make mistakes and exhibit their own biases,” Google added.
Read the full Google AI blog here.



0 Comments
Leave a Reply